DifyのRAG精度が低い?GenSparkとGeminiで高精度チャットボットを自作する方法【コード付】
目次
1. DifyのRAG精度に限界を感じていませんか?
「企業サイトのチャットボットって、なぜあんなに的外れな回答ばかりなのか?」
自身で開発したコミュニティアプリに「ジェンスパーク(GenSpark)」のサポートボットを導入しようとした際、私はこの疑問にぶつかりました。「FAQのリンクを貼るだけなら検索でいい」「知りたいのはそこじゃない」——そんなユーザー体験を避けるため、「本当に納得できる精度のチャットボット」を自作することにしました。
2. Difyのナレッジベース構築で直面した「3つの壁」
当初は、人気のローコード開発ツール「Dify」を使用してRAG(検索拡張生成)システムを構築しました。ブログ記事をインポートし、自動でベクトル化してくれる便利な機能です。
しかし、3日間かけてチューニングを行いましたが、以下の問題が解決しませんでした。
- 情報の断片化:記事の一部だけが検索され、文脈が無視される。
- ハルシネーション:似た単語に引っ張られ、無関係な記事を元に嘘をつく。
- 「分かりません」の連発:検索スコアの閾値を上げると、今度は何も答えなくなる。
ここで私は仮説を立てました。「検索(Retrieval)に頼るRAGという仕組み自体が、今回の規模感には合っていないのではないか?」と。
3. 解決策:GenSparkナレッジ × Geminiロングコンテキスト
そこで、アプローチを「検索」から「全読ませ」に切り替えました。以下の3ステップ構成です。
- GenSpark (データ生成):ブログ記事をAIに読ませ、「完璧なQ&Aリスト」を生成させる。
- Cloudflare Workers (実行環境):生成したナレッジをKVに保存し、API化する。
- Gemini 1.5 Flash (頭脳):ナレッジ全文をプロンプトに含めて回答させる。
4. 実装コード解説:Cloudflare Workers + Hono
実際に2時間で組み上げたバックエンドのコード(抜粋)を公開します。フレームワークには軽量なHonoを使用しています。
コアロジック:ナレッジ全渡しとNO_ANSWER制御
このコードのポイントは、KVから取得したナレッジをそのままGeminiに投げている点と、ボットが適当なことを言わないための制御です。
import { Hono } from 'hono'
import { cors } from 'hono/cors'
const app = new Hono()
app.use('/*', cors())
// メインの返信エンドポイント
app.post('/api/reply', async (c) => {
try {
const body = await c.req.json()
const { content } = body // ユーザーの投稿内容
// 1. ナレッジベース(KV)から全テキストを取得
// RAG(検索)はせず、ここですべて読み込む
const knowledge = await c.env.KV.get('kb:all', 'text')
if (!knowledge) {
return c.json({ error: 'Knowledge base error' }, 500)
}
// 2. Gemini APIで回答生成
const answer = await generateAnswer(content, knowledge, c.env.GEMINI_API_KEY)
// 3. ナレッジ外の質問なら無視する(重要!)
// コミュニティのノイズにならないよう、分からないことは答えない
if (answer === 'NO_ANSWER' || answer.trim() === 'NO_ANSWER') {
console.log('[BOT] ナレッジベース外のためスキップ')
return c.json({
status: 'no_answer',
message: '該当情報なし'
})
}
// ... (以下、投稿処理へ続く)
return c.json({ status: 'success', answer })
} catch (error) {
return c.json({ error: error.message }, 500)
}
})
export default app実際の動作画面
以下は、コミュニティアプリで実際に稼働しているボットの様子です。ユーザーから「Thinkingループ」について質問があり、ボットが適切に回答している場面です。
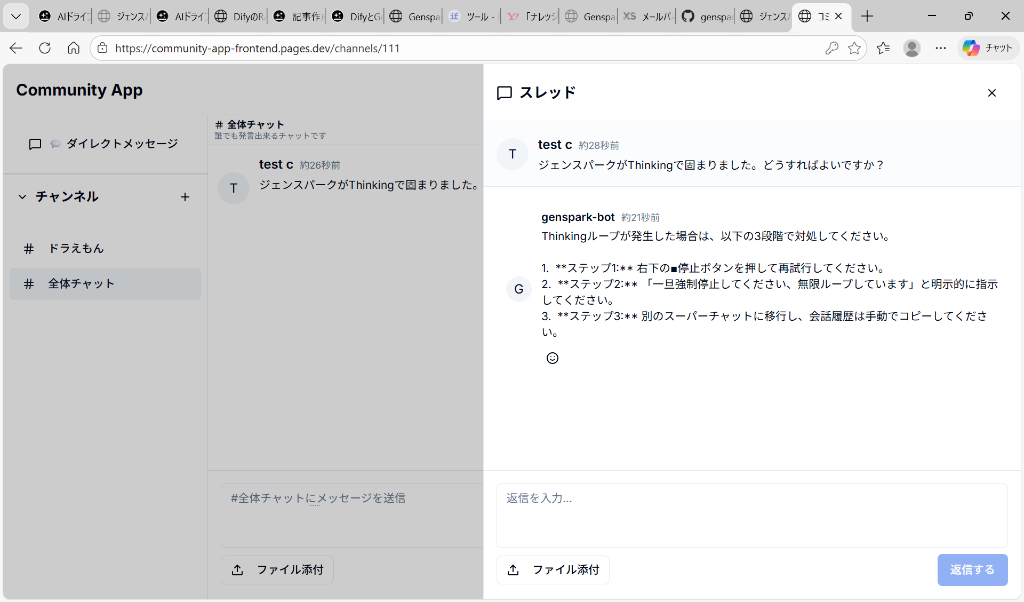
図:GenSparkボットがユーザーの質問に回答している様子
この画面からも分かるように、ボットは「Thinkingループが発生した場合」という具体的な対処法を、ナレッジベースから正確に抽出して回答しています。DifyのRAGでは難しかった、この「文脈を理解した的確な回答」が実現できています。
5. ボットの性格を決めるプロンプト設計のコツ
Geminiに渡すプロンプト(指示書)も重要です。単に答えるだけでなく、「コミュニティボットとしての立ち振る舞い」を制御しています。
async function generateAnswer(question, knowledge, apiKey) {
const prompt = `あなたはGensparkコミュニティのサポートボットです。
【重要なルール】
1. 以下のナレッジベースに記載されている情報のみを使用してください
2. ナレッジベースに該当する情報がない場合は「NO_ANSWER」とだけ返してください
3. 不具合について謝罪しないでください(あなたは公式ではなく、有志のツールです)
4. 挨拶や前置きは最小限にし、結論から答えてください
5. 雑談には付き合わず「NO_ANSWER」としてください
ナレッジベース:
${knowledge}
ユーザーの質問: ${question}
回答:`
// ... (Gemini API呼び出し処理)
}特に「謝罪禁止」の指示が効果的です。AIはすぐに「ご不便をおかけして申し訳ありません」と言いたがりますが、非公式ボットがこれをやるとユーザーが混乱します。この制御により、非常に「役に立つ」ボットになりました。
6. まとめ:適材適所のAI開発を
Difyで3日間悩んだ開発が、構成を変えるだけでわずか2時間で完了しました。 稼働後のテストでも、私の嫌いだった「ズレた回答」は一度も発生していません。
もしあなたが今、DifyやLangChainでのRAG構築、精度の低さに疲弊しているなら、一度立ち止まって考えてみてください。 「そのドキュメント、今のAIなら全部読めるのでは?」
GenSparkで整理し、Geminiで読む。 このシンプルな構成こそが、個人開発における最強のソリューションになるかもしれません。